



"The golden truth can't be self-referential. It has to be grounded in something outside the model."
In the last piece I wrote about the puppeteer problem: one human, ten agents, and the oversight gap that opens up when AI can do the work but nobody can verify it was done right. That piece was about the general case. This one is about a specific, harder instance of the same problem: what happens when you try to extract the complete truth about a system that's been running for decades?
A modernization that worked, until it didn't
A team I spoke with last year proudly demoed a "complete" modernization from a thirty-year-old order system. They'd used an LLM to convert the code, a schema tool to map the database, and every test passed. Six weeks into production, about one in eight orders started failing silently.
The error logs said nothing. It took two engineers, one retired expert brought back as a consultant, and three weeks to find it. A single field in the old system, called PRINT_COMMENT, had been used for twenty years to carry a three-letter gate code that told the warehouse drivers which entry to use. The migration had mapped it, literally, to a print_comment field in the new system. Every order with a gate code now printed "ABC" on the packing slip and went nowhere.
The code was right. The schema was right. The migration was wrong.
That's the shape of the problem. Not a translation problem, a verification problem. And verification can't be done by the same machinery that did the translation.
Four sources, one truth
Most modernization tools treat code as the single source of truth. Parse it, translate it, ship it. But code is one perspective on a system, and often a degraded one. Decades of patches, workarounds, and undocumented changes mean the code tells you what the system does today, not what it was meant to do or why.
We built MYRA around the idea that truth requires triangulation. Four sources: expert sessions that capture the "why" and the tribal knowledge. Legacy code that captures the "what." Data dictionaries that capture the structure. Documentation that captures what someone once believed to be true. None of those alone is the truth. Each one is partial, possibly stale, possibly wrong.
The golden truth is what emerges when you reconcile them.

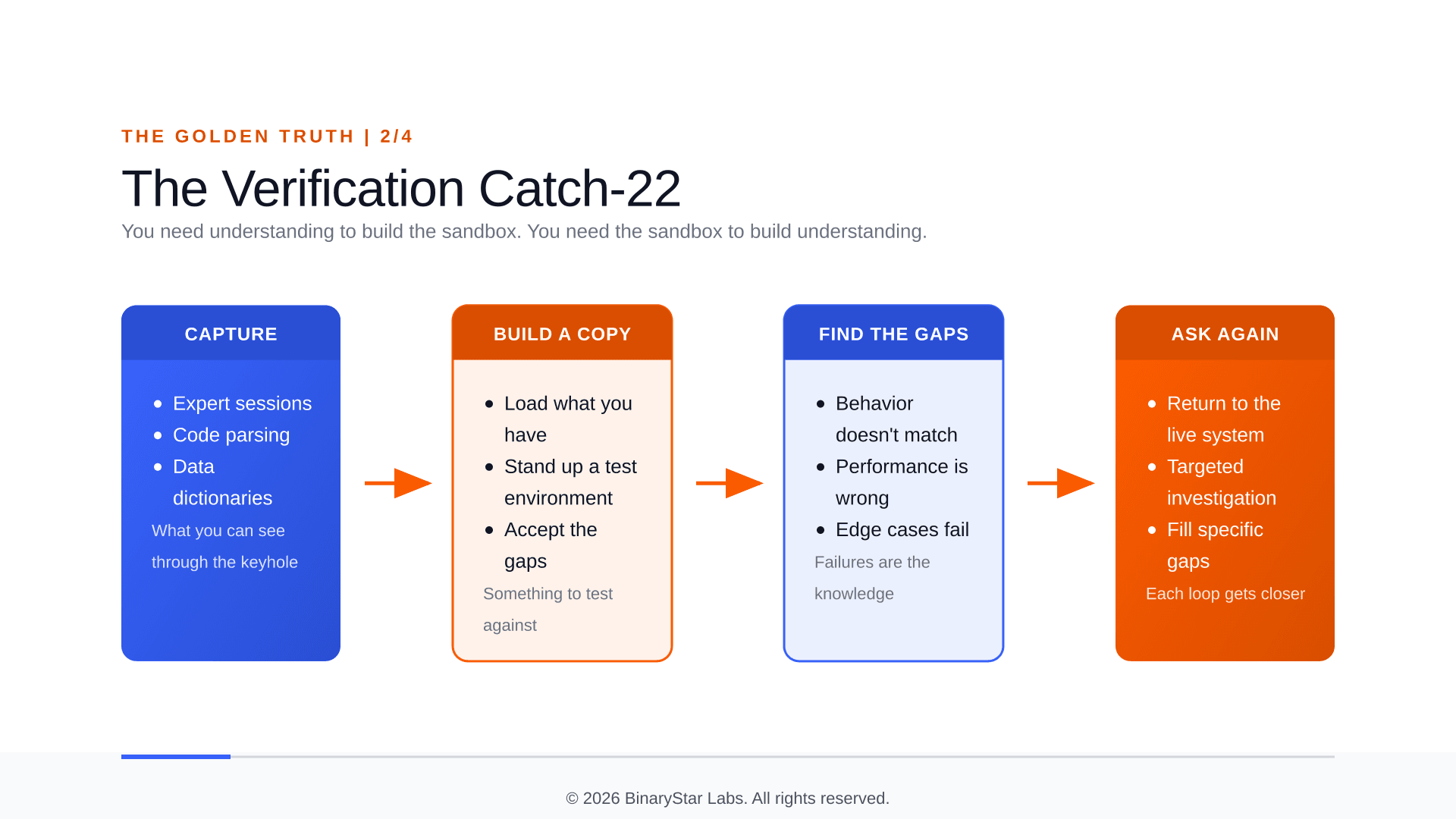
The catch-22
Here's where it gets hard. To verify that your understanding of a legacy system is correct, you need to test it against the real thing. But testing against a live production system is reckless. So you need a safe copy. But to build a faithful copy, you need to understand the system configuration, the OS-level tuning, the indices, the file parameters. And that knowledge is locked inside the system you need a safe copy to investigate.
You can't fully inventory the live system because you don't know all the right questions to ask. Systematic exploration with an agent needs a safe environment to run in, and building that safe environment needs the knowledge you don't yet have. Three walls of the same room, no door.
The only way out is iterative. Start with what you can get. Build an imperfect copy. Discover what's wrong with it. Use those gaps to figure out what you missed. Go back, ask better questions. Repeat. Each loop gets you closer. But you never get a clean starting point.
The mess is where the business lives
And then there's the data. A phone number field that holds an account reference because someone ran out of fields twenty years ago. An address line that contains delivery instructions because there was nowhere else to put them. A status field with twelve official values and forty unofficial ones that someone invented to track a workflow the system was never built to handle.
That's not dirty data. That's the business finding a way to function despite the system's limitations. Remove that field or enforce validation and you break something nobody can articulate as a requirement because it was never designed. It evolved.
An LLM won't find this in its training data. There's no Stack Overflow post about a particular retailer's address field conventions. But it can spot the pattern: 30% of records in a numeric field contain text. That's a signal. The expert fills in the meaning: "Oh, those are our wholesale customers. The drivers need special instructions."
That's an undocumented business process hiding in data anomalies. If you migrate by mapping fields to their official definitions, you lose it silently.

It's about the questions, not the answers
This is what changed my thinking. The golden truth isn't a database of facts about your legacy system. It's a structured collection of questions at various stages of resolution.
The real value isn't capturing knowledge. It's surfacing inconsistencies and giving you a way to ask questions about them. The address field that contradicts its schema. The business rule the expert describes that doesn't match what the code does. The index that exists on production but nobody knows why.
Take PRINT_COMMENT from the earlier story. In a naive migration it's one line in a mapping table. In this model it has a life cycle.
It begins as an anomaly: an agent notices that a third of the values in PRINT_COMMENT match a three-character uppercase pattern, which is not what a print comment is supposed to look like. On its own that is nothing, a curiosity, a blip in the data. Then the system tries to resolve it from the sources it already has. The data dictionary has no mention of region codes. The code doesn't branch on three-letter values. The documentation is silent. Now the curiosity is a question with weight.
An expert is shown the pattern, not asked to produce it. "Oh," she says, "those are gate codes for the warehouse drivers. DHL made us do that when they took over the route." The question resolves. It becomes a rule with an operational constraint attached: if PRINT_COMMENT matches the pattern, route by gate; otherwise treat as a comment. It lives in the system as a tested assertion, and a year from now somebody who touches the order module will see not just the answer but the path by which we got there.
That path is the part no other method produces. Interviews skip it. Documentation skips it. An LLM reading the code can't see it because it was never written down.
Each inconsistency is a thread to pull. Some resolve quickly through cross-referencing sources, others need the expert's time, and a long tail remains open, flagged honestly as unverified. The progress of a migration isn't "how much have we captured" but "how many questions have we resolved" and, more uncomfortably, "how many are still open."
This also changes the expert's role. You're not asking for a brain dump of everything they know. You're showing them specific inconsistencies and asking "what's going on here?" People are much better at reacting to something concrete than generating knowledge from scratch. The inconsistencies are the concrete. The expert's memory is the glue that connects them back to intent.
The golden truth emerges from resolving inconsistencies, not from capturing facts. Put a sharper way: the work of a migration isn't to translate a system, it's to rebuild the tacit agreement that built the system, one surfaced contradiction at a time. That's slower than an LLM promises. It's also the only path that produces a migration you can still trust a year later, when an order fails and somebody has to walk downstairs and say why.

Find the questions hiding in your legacy system
If you're staring at a legacy system you can't modernize because you can't trust your inventory of it, book a MYRA Discovery session. It's a 30-minute call, no commitment. We'll discuss your environment, the module that most worries you, and whether a MYRA pilot is the right next step.
If it is, the pilot is a fixed-price, seven-week engagement that reconciles four sources (expert sessions, code, data, docs) against a single contained module. You leave with a verified knowledge base, a documentation drift report, a business-rule inventory, and the evidence to make an informed go/no-go decision on the rest of the system. Everything we produce is yours, regardless of whether you proceed. We'll walk you through the full structure on the call.
The next piece in this series, The judgment you can't afford to lose, is about where this knowledge actually comes from: the expert sessions themselves, and why the screen is the wrong place to look when you're trying to capture what an expert knows.
Hans Speijer is a co-founder of BinaryStar Labs, where he leads development of MYRA, an AI platform for legacy system modernization. MYRA captures knowledge from four sources and converges toward a verified understanding of systems that have been running longer than most of us have been coding. Previous piece in this series: The Puppeteer Problem.


