



The two hundred thousand dollars nobody logged
It's 8:47 on a Wednesday. A senior fraud analyst at a mid-size bank opens her queue. She sorts the flagged transactions by amount, scrolls past thirty-eight rows, pauses on one for four seconds, scrolls past twelve more, pauses on another for six, clears the rest of the queue, and goes to lunch.
A session replay of those fourteen minutes shows forty-six mouse movements and two dwells. What it can't tell you is that she just cleared two hundred thousand dollars of transactions by deciding not to act on any of them. The two she paused on were near-matches to a pattern she'd rejected the week before, because she recognised the merchants as legitimate repeat customers.
Now multiply that across a fraud floor. Across claims. Across contact centres, back offices, security operations, and every other place where a senior expert clears a queue that a junior can't. That's tens of millions of dollars a day in judgment that leaves no trail, no audit record, and no training data. When she retires next year, that judgment walks out of the door with her.
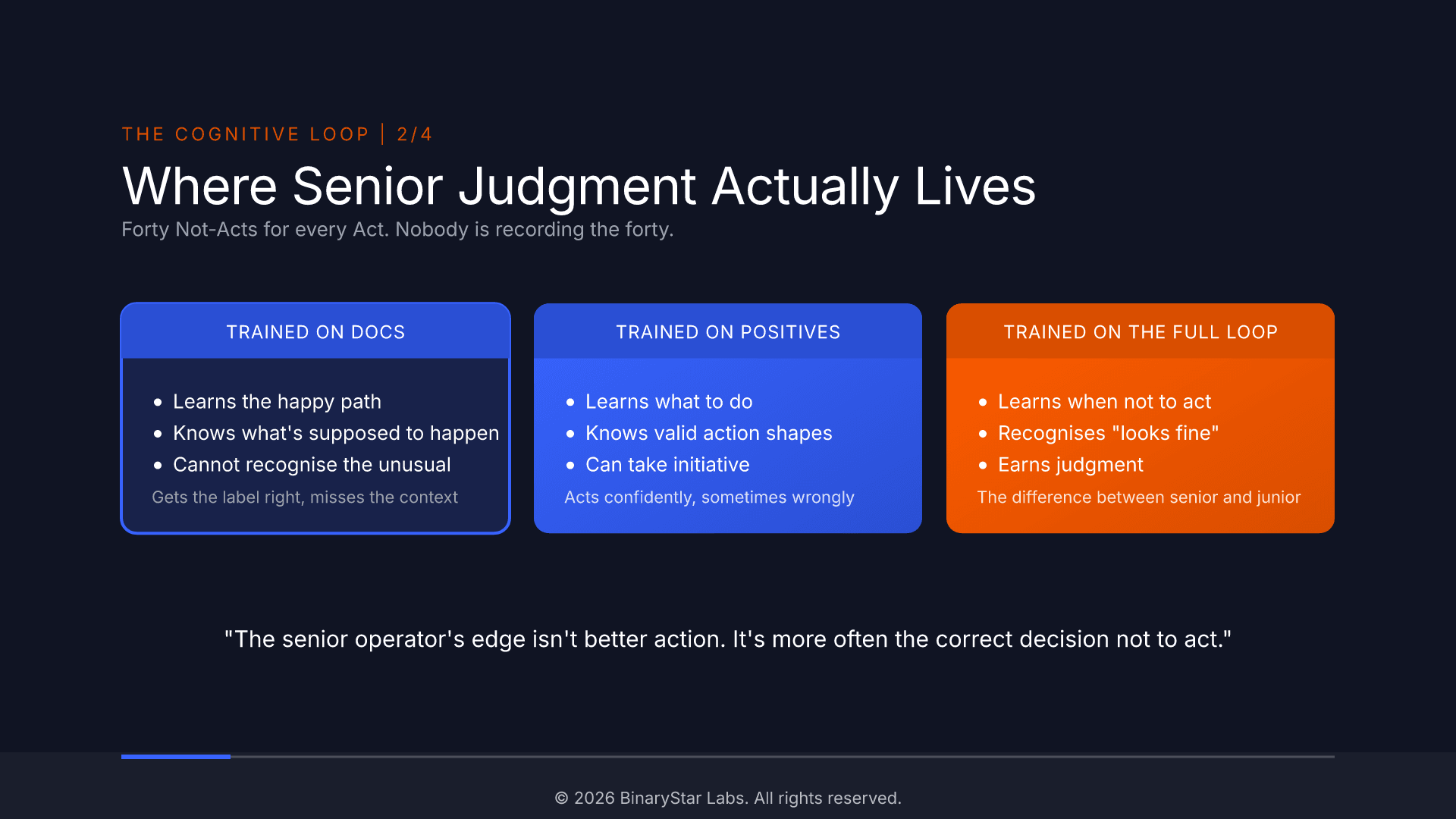
"The senior operator's edge isn't better action. It's more often the correct decision not to act."
Why your existing tools can't see it
You already pay for a stack of software that claims to record what users do. Session replay, CRM audit logs, case-management trails, enterprise search over your wikis and SOPs. They capture pixels, clicks, timestamps, and what was supposed to happen. None of them captures why the analyst paused on one row and moved past twelve. That reasoning is what separates a senior operator from a junior one, and it lives in none of the systems you pay for.
How this is different from what you already pay for
| What it records | What it answers | What it misses | |
|---|---|---|---|
| Session replay (Hotjar, FullStory) | Pixels, clicks, mouse paths | "What did the screen look like when the user clicked?" | Why the expert paused, filtered, or moved on |
| Enterprise search (Glean, Notion AI) | Documents, wikis, SOPs | "What does the designed process say?" | What experts actually do when the data is in front of them |
| MYRA | Expert decisions in context | "What was the expert reasoning about, and what did they choose to do (or not do)?" | Nothing that's visible on the screen |
You aren't being asked to replace any of these. You're being asked to capture the one thing none of them can see: the reasoning that turns a queue of data into a decision.
The loop underneath every expert's day
Sit behind a claims analyst for thirty minutes. They open a queue, filter it, scan the grid, hesitate on one row, look, close it, move on. Repeat. Sit behind a fraud analyst, a support lead, a triage nurse, a dispatcher. Same pattern. Four moves, over and over: navigate to something they're curious about, evaluate what they find, act on it, or decide not to.
That last move, decide not to, is the one nobody records. An analyst scans forty rows and moves on. A reviewer reads a case and closes the tab. A support agent reads a complaint and routes it on. Each is a decision: "I looked, and nothing warranted action." In most operations, forty of those happen for every one action. That's where most of the judgment lives, and it's invisible to every tool you already own.
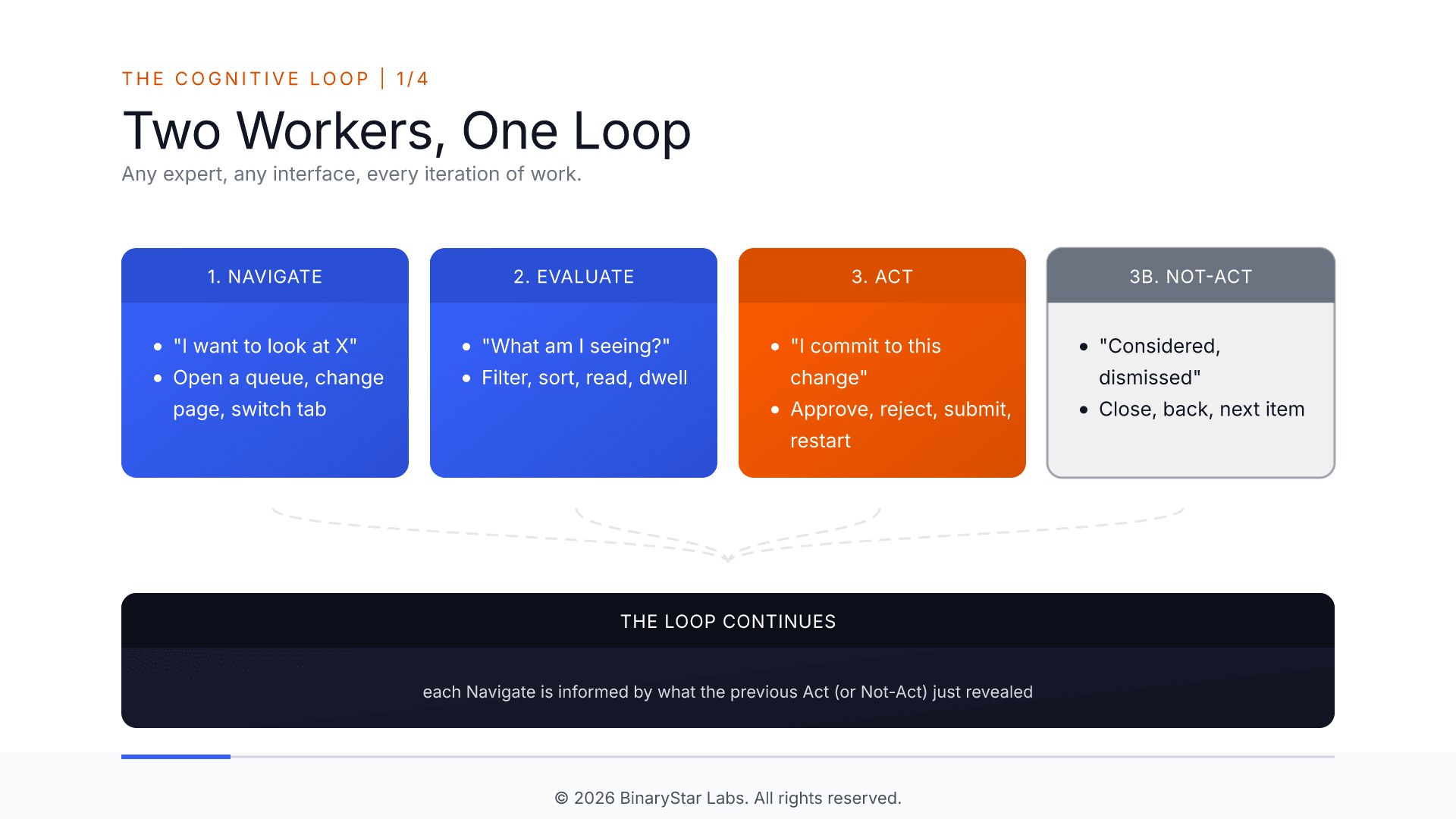
What MYRA actually captures, in plain English
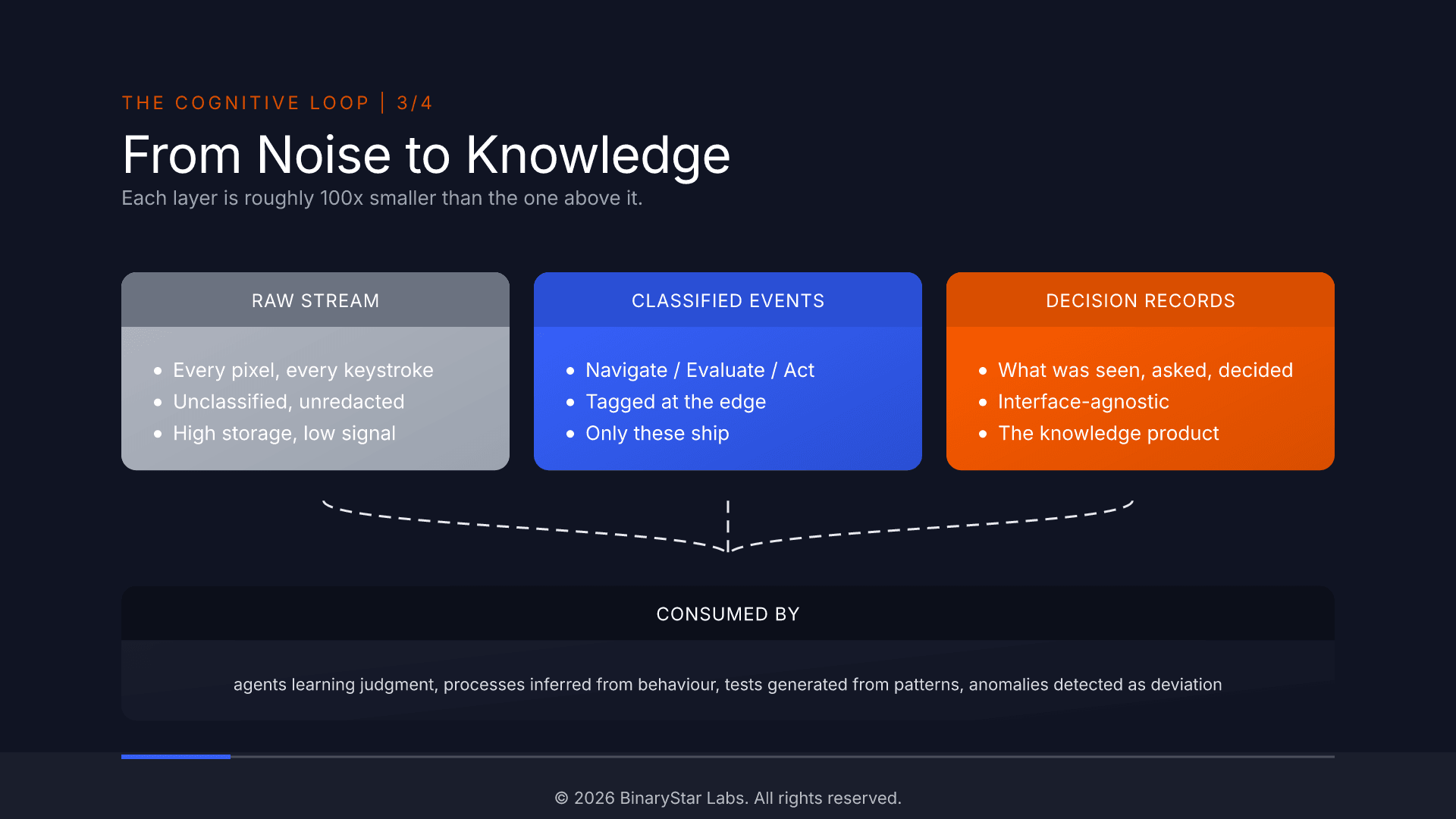
For each session we produce one short record per decision. Each record says: what the expert was looking at, what they were trying to figure out, and what they chose to do (or not do). That's it. No screen recording. No keystroke dump. No replay.
In a claims queue, an analyst filtered for "pending claims over ten thousand dollars", sorted by age, dwelled on four rows for eight seconds each, then rejected claim 12347.
That sentence is the product. The clicks, the keystrokes, the rendered pixels, the network traffic: all raw material. The record is what you keep, what you train an AI on, and what outlives the person who made the call.
From noise to knowledge
Across a thousand sessions you get something no other source in your stack produces: a body of expert reasoning grounded in what the expert actually saw and the criteria they actually applied. Not interviews (people tell you what they think they do). Not documentation (it describes the designed system, not the real one). Not screen recordings (pixels without reasoning). What the expert actually does, when the real data is in front of them.
One sensor today, many sensors tomorrow
A browser is one sensor. A terminal is another. A voice channel will be a third. An API client, a fourth. They all produce the same kind of record. A support agent on the phone, an operator in a shell, and a claims reviewer in a browser, all working on the same incident, produce one coherent timeline of the organisation's response. The AI you train on that timeline doesn't need to know which part came from a keyboard and which came from a mouse. The shape of a decision is the same.
We started with terminal capture (running quietly in production at BinaryStar Labs for several months). Browser capture completes the pair. Voice is next.

What you're losing if you don't
In three years, the person who knows how to clear that fraud queue will have retired, moved internally, or left for a competitor. If you haven't captured how she clears it, you are rebuilding her from scratch. The junior operator who replaces her will approve and reject the same transactions, but without her forty Not-Acts of judgment. You won't find out until the losses show up in the monthly numbers.
Every day of senior expert judgment that isn't captured is a day your organisation is one headcount change away from losing knowledge you can't buy back.
See what your experts' judgment looks like captured
If you run a fraud, claims, support, or operations team and want to understand what captured expert judgment would look like in your environment, book a MYRA Discovery session. It's a 30-minute call, no commitment. We'll talk about your environment, the judgment that's walking out the door when senior people leave, and whether a scoped pilot is the right next step.
If it is, the pilot is a fixed-price, seven-week engagement on a contained module or process: expert capture, business-rule extraction, drift detection against existing documentation, and a verified knowledge base you own regardless of how you proceed. We'll walk you through the full structure on the call.
Hans Speijer is a co-founder of BinaryStar Labs, where he leads development of MYRA, an AI platform for capturing and governing expert knowledge. Previous piece in this series: The golden truth problem.


